Optimize Data Locality
At the end of the previous chapter we saw that although we’ve moved the most compute intensive parts of the application to the accelerator, sometimes the process of copying data from the host to the accelerator and back will be more costly than the computation itself. This is because it’s difficult for a compiler to determine when (or if) the data will be needed in the future, so it must be cautious and ensure that the data will be copied in case it’s needed. To improve upon this, we’ll exploit the data locality of the application. Data locality means that data used in device or host memory should remain local to that memory for as long as it’s needed. This idea is sometimes referred to as optimizing data reuse or optimizing away unnecessary data copies between the host and device memories. However you think of it, providing the compiler with the information necessary to only relocate data when it needs to do so is frequently the key to success with OpenACC.
After expressing the parallelism of a program’s important regions it’s frequently necessary to provide the compiler with additional information about the locality of the data used by the parallel regions. As noted in the previous section, a compiler will take a cautious approach to data movement, always copying data that may be required, so that the program will still produce correct results. A programmer will have knowledge of what data is really needed and when it will be needed. The programmer will also have knowledge of how data may be shared between two functions, something that is difficult for a compiler to determine. Profiling tools can help the programmer identify when excess data movement occurs, as will be shown in the case study at the end of this chapter.
The next step in the acceleration process is to provide the compiler with additional information about data locality to maximize reuse of data on the device and minimize data transfers. It is after this step that most applications will observe the benefit of OpenACC acceleration. This step will be primarily beneficial on machines where the host and device have separate memories.
Data Regions
The data construct facilitates the sharing of data between multiple
parallel regions. A data region may be added around one or more parallel
regions in the same function or may be placed at a higher level in the program
call tree to enable data to be shared between regions in multiple functions.
The data construct is a structured construct, meaning that it must begin and
end in the same scope (such as the same function or subroutine). A later
section will discuss how to handle cases where a structured construct is not
useful. A data region may be added to the earlier parallel loop example to
enable data to be shared between both loop nests as follows.
#pragma acc data
{
#pragma acc parallel loop
for (i=0; i<N; i++)
{
y[i] = 0.0f;
x[i] = (float)(i+1);
}
#pragma acc parallel loop
for (i=0; i<N; i++)
{
y[i] = 2.0f * x[i] + y[i];
}
}
!$acc data
!$acc parallel loop
do i=1,N
y(i) = 0
x(i) = i
enddo
!$acc parallel loop
do i=1,N
y(i) = 2.0 * x(i) + y(i)
enddo
!$acc end data
The data region in the above examples enables the x and y arrays to be
reused between the two parallel regions. This will remove any data copies
that happen between the two regions, but it still does not guarantee optimal
data movement. In order to provide the information necessary to perform optimal
data movement, the programmer can add data clauses to the data region.
Note: An implicit data region is created by each parallel and kernels
region.
Data Clauses
Data clauses give the programmer additional control over how and when data is
created on and copied to or from the device. These clauses may be added to any
data, parallel, or kernels construct to inform the compiler of the data
needs of that region of code. The data directives, along with a brief
description of their meanings, follow.
copy- Create space for the listed variables on the device, initialize the variable by copying data to the device at the beginning of the region, copy the results back to the host at the end of the region, and finally release the space on the device when done.copyin- Create space for the listed variables on the device, initialize the variable by copying data to the device at the beginning of the region, and release the space on the device when done without copying the data back the the host.copyout- Create space for the listed variables on the device but do not initialize them. At the end of the region, copy the results back to the host and release the space on the device.create- Create space for the listed variables and release it at the end of the region, but do not copy to or from the device.present- The listed variables are already present on the device, so no further action needs to be taken. This is most frequently used when a data region exists in a higher-level routine.deviceptr- The listed variables use device memory that has been managed outside of OpenACC, therefore the variables should be used on the device without any address translation. This clause is generally used when OpenACC is mixed with another programming model, as will be discussed in the interoperability chapter.
In the case of the copy, copyin, copyout and create clause, their
intended functionality will not occur if the variable referenced already
exists within device memory. It may be helpful to think of these clauses
as having an implicit present clause attached to them, where if the variable
is found to be present on the device, the other clause will be ignored.
An important example of this behavior is that using the copy clause
when the variable already exists within device memory will not copy any
data between the host and device. There is a different directive for
copying data between the host and device from within a data region, and
will be discussed shortly.
Shaping Arrays
Sometimes a compiler will need some extra help determining the size and shape of arrays used in parallel or data regions. For the most part, Fortran programmers can rely on the self-describing nature of Fortran arrays, but C/C++ programmers will frequently need to give additional information to the compiler so that it will know how large an array to allocate on the device and how much data needs to be copied. To give this information the programmer adds a shape specification to the data clauses.
In C/C++ the shape of an array is described
as x[start:count] where x is the variable name, start is the first element to be copied and
count is the number of elements to copy. If the first element is 0, then it
may be left off, taking the form of x[:count].
In Fortran the shape of an array is described as x(start:end) where x is the
variable name, start is the first element to be copied and end is the last element
to be copied. If start is the beginning of the array or end is the end of the array,
they may be left off, taking the form of x(:end), x(start:) or x(:).
Array shaping is frequently necessary in C/C++ codes when the OpenACC appears inside of function calls or the arrays are dynamically allocated, since the shape of the array will not be known at compile time. Shaping is also useful when only a part of the array needs to be stored on the device.
As an example of array shaping, the code below modifies the previous example by adding shape information to each of the arrays.
#pragma acc data create(x[0:N]) copyout(y[0:N])
{
#pragma acc parallel loop
for (i=0; i<N; i++)
{
y[i] = 0.0f;
x[i] = (float)(i+1);
}
#pragma acc parallel loop
for (i=0; i<N; i++)
{
y[i] = 2.0f * x[i] + y[i];
}
}
!$acc data create(x(1:N)) copyout(y(1:N))
!$acc parallel loop
do i=1,N
y(i) = 0
x(i) = i
enddo
!$acc parallel loop
do i=1,N
y(i) = 2.0 * x(i) + y(i)
enddo
!$acc end data
In this example, the programmer knows that both x and y will
be populated with data on the device, so neither need to have data copied
from the host. However, since y is used within a copyout clause,
the data contained within y will be copied from the device to the host
when the end of the data region is reached. This is useful in a situation
where you need the results stored in y later in host code.
Unstructured Data Lifetimes
While structured data regions are sufficient for optimizing the data
locality in many program, they are not sufficient for some cases, particularly
those using Object Oriented coding practices, or when wanting to manage device
data across different code files. For example, in a C++ class data
is frequently allocated in a class constructor, deallocated in the destructor,
and cannot be accessed outside of the class. This makes using structured data
regions impossible because there is no single, structured scope where the
construct can be placed. For these situations we can use
unstructured data lifetimes. The enter data and exit data directives can be
used to identify precisely when data should be allocated and deallocated on the
device.
The enter data directive accepts the create and copyin data clauses and
may be used to specify when data should be created on the device.
The exit data directive accepts the copyout and a special delete data
clause to specify when data should be removed from the device.
If a variable appears in multiple enter data directives, it will only be
deleted from the device if an equivalent number of exit data directives
are used. To ensure that the data is deleted, you can add the finalize
clause to the exit data directive. Additionally, if a variable appears
in multiple enter data directives, only the instance will do any
host-to-device data movement. If you need to move data between the host
and device any time after data is allocated with enter data, you should
use the update directive, which is discussed later in this chapter.
C++ Class Data
C++ class data is one of the primary reasons that unstructured data lifetimes
were added to OpenACC. As described above, the encapsulation provided by
classes makes it impossible to use a structured data region to control the
locality of the class data. Programmers may choose to use the unstructured data
lifetime directives or the OpenACC API to control data locality within a C++
class. Use of the directives is preferable, since they will be safely ignored
by non-OpenACC compilers, but the API is also available for times when the
directives are not expressive enough to meet the needs of the programmer. The
API will not be discussed in this guide, but is well-documented on the OpenACC
website.
The example below shows a simple C++ class that has a constructor, a destructor, and a copy constructor. The data management of these routines has been handled using OpenACC directives.
template <class ctype> class Data
{
private:
/// Length of the data array
int len;
/// Data array
ctype *arr;
public:
/// Class constructor
Data(int length)
{
len = length;
arr = new ctype[len];
#pragma acc enter data copyin(this)
#pragma acc enter data create(arr[0:len])
}
/// Copy constructor
Data(const Data<ctype> &d)
{
len = d.len;
arr = new ctype[len];
#pragma acc enter data copyin(this)
#pragma acc enter data create(arr[0:len])
#pragma acc parallel loop present(arr[0:len],d)
for(int i = 0; i < len; i++)
arr[i] = d.arr[i];
}
/// Class destructor
~Data()
{
#pragma acc exit data delete(arr)
#pragma acc exit data delete(this)
delete arr;
len = 0;
}
};
Notice that an enter data directive is added to the class constructor to
handle creating space for the class data on the device. In addition to the data
array itself the this pointer is copied to the device. Copying the this
pointer ensures that the scalar member len, which denotes the length of the
data array arr, and the pointer arr are available on the accelerator as
well as the host. It is important to place the enter data directive after the
class data has been initialized. Similarly exit data directives are added to
the destructor to handle cleaning up the device memory. It is important to
place this directive before array members are freed, because once the host
copies are freed the underlying pointer may become invalid, making it impossible
to then free the device memory as well. For the same reason the this pointer
should not be removed from the device until after all other memory has been
released.
The copy constructor is a special case that is worth looking at on its own. The
copy constructor will be responsible for allocating space on the device for the
class that it is creating, but it will also rely on data that is managed by the
class being copied. Since OpenACC does not currently provide a
portable way to copy from one array to another, like a memcpy on the host, a
loop is used to copy each individual element from one array to the other.
Because we know that the Data object passed in will also have its members on
the device, we use a present clause on the parallel loop to inform the
compiler that no data movement is necessary.
The same technique used in the class constructor and destructor above can be
used in other programming languages as well. For instance, it’s common practice
in Fortran codes to have a subroutine that allocate and initialize all arrays
contained within a module. Such a routine is a natural place to use an enter data region, as the allocation of both the host and device memory will appear
within the same routine in the code. Placing enter data and exit data
directives in close proximity to the usual allocation and deallocation of data
within the code simplifies code maintenance.
Update Directive
Keeping data resident on the accelerator is often key to obtaining high
performance, but sometimes it’s necessary to copy data between host and device
memories. The update directive provides a way to explicitly
update the values of host or device memory with the values of the other. This
can be thought of as synchronizing the contents of the two memories. The
update directive accepts a device clause for copying data from the host to
the device and a self clause for updating from the device to local memory,
which is the host memory.
As an example of the update directive, below are two routines that may be
added to the above Data class to force a copy from host to device and device
to host.
void update_host()
{
#pragma acc update self(arr[0:len])
;
}
void update_device()
{
#pragma acc update device(arr[0:len])
;
}
The update clauses accept an array shape, as already discussed in the data
clauses section. Although the above example copies the entire arr array to or
from the device, a partial array may also be provided to reduce the data
transfer cost when only part of an array needs to be updated, such as when
exchanging boundary conditions.
Best Practice: As noted earlier in the document, variables in an OpenACC code
should always be thought of as a singular object, rather than a host copy and
a device copy. Even when developing on a machine with a unified host and
device memory it is important to include an update directive whenever
accessing data from the host or device that was previously written to by the
other, as this ensures correctness on
all devices. For systems with distinct memories, the update will synchronize
the values of the affected variable on the host and the device. On devices with
a unified memory, the update will be ignored, incurring no performance penalty.
In the example below, omiting the update on line 17 will produce different
results on a unified and non-unified memory machine, making the code
non-portable.
for(int i=0; i<N; i++)
{
a[i] = 0;
b[i] = 0;
}
#pragma acc enter data copyin(a[0:N])
#pragma acc parallel loop
{
for(int i=0; i<N; i++)
{
a[i] = 1;
}
}
#pragma acc update self(a[0:N])
for(int i=0; i<N; i++)
{
b[i] = a[i];
}
#pragma acc exit data
Best Practice: Offload Inefficient Operations to Maintain Data Locality
Due to the high cost of PCIe data transfers on systems with distinct host and
device memories, it’s often beneficial to move sections of the application to
the accelerator device, even when the code lacks sufficient parallelism to see
direct benefit. The performance loss of running serial or code with a low
degree of parallelism on a parallel accelerator is often less than the cost of
transferring arrays back and forth between the two memories. A developer may
use a parallel region with just 1 gang as a way to offload a serial section
of the code to the accelerator. For instance, in the code below the first and
last elements of the array are host elements that need to be set to zero. A
parallel region (without a loop) is used to perform the parts that are
serial.
#pragma acc parallel loop
for(i=1; i<(N-1); i++)
{
// calculate internal values
A[i] = 1;
}
#pragma acc parallel
{
A[0] = 0;
A[N-1] = 0;
}
!$acc parallel loop
do i=2,N-1
! calculate internal values
A(i) = 1
end do
!$acc parallel
A(1) = 0;
A(N) = 0;
!$acc end parallel
In the above example, the second parallel region will generate and launch a
small kernel for setting the first and last elements. Small kernels generally
do not run long enough to overcome the cost of a kernel launch on some
offloading devices, such as GPUs. It’s important that the data transfer saved
by employing this technique is large enough to overcome the high cost of a
kernel launch on some devices. Both the parallel loop and the second
parallel region could be made asynchronous (discussed in a later chapter) to
reduce the cost of the second kernel launch.
Note: Because the kernels directive instructs the compiler to search for
parallelism, there is no similar technique for kernels, but the parallel
approach above can be easily placed between kernels regions.
Best Practice: Dealing with C++ End/Last Pointers
It is a common practice for list/array-like objects in C++ to store two pointers, one to the first element and one that points to a memory address immediately following the last element. This pattern can be found in the C++ Standard Template Library, for instance. Below is an example:
const size_t N = 1024;
float *first = (float*)malloc(N * sizeof(float));
float *last = first + N; // Beyond the allocated memory
This pattern works fine on machines with a single address space, however can
be problematic on machines with discrete host and device memory spaces.
The default behavior for scalar pointer variables used in parallel or
serial regions is to treat the pointer implicitly as-if it had appeared
in a firstprivate clause. Consider the following code, however, which
would break on a discrete memory machine.
#pragma acc parallel loop copy(first[0:1024])
for (int i = 0; i < 1024 ; i++)
{
// first is a device address
// last is a host address
if ( first != last )
{
first[i] = (float)i;
}
}
Because first has been copied to the device, within the parallel region
the device address will be used, but since last is implicitly firstprivate
it will contain the host address. The last pointer does not actually point
to any data and must remain relative to first in device memory, so
attempting to copy it doesn’t make sense. There is an unintuitive solution
to this problem, however.
#include <cstdio>
#include <cstdlib>
int main(int argc, char **argv)
{
float *first = (float*)malloc(1024 * sizeof(float));
float *last = first + 1024;
#pragma acc parallel loop copy(first[0:1024]) copy(last[-1:0])
for (int i = 0; i < 1024 ; i++)
{
if ( first != last )
{
first[i] = (float)i;
}
}
printf("[%d] %f : [%d] %f\n", 0, first[0], 1023, first[1023]);
free(first);
return 0;
}
In this example we are copying the element immediately before last
and copying zero elements. This may be surprising, since C++ does not
have arbitrary array bounds and copying zero elements seems nonsensical.
What happens, however, is that a present table entry is created for
last and, because we’re saying to copy the element before last,
we’re copying data that is already present on the device (which is defined
as not copying any additional data). With this change, both first
and last will use device addresses and will be relative to the same
base address.
Note: As-written this code assumes that the data clauses are evaluated from left to right, which is not strictly required. If processed from right to left the overlap between the two regions would likely result in a partially present error, since some of the memory already exists in the present table. At the time of writing OpenACC 3.4 is the current version and defining more tightly the order of operations to prevent this issue is a deferred topic.
Case Study - Optimize Data Locality
By the end of the last chapter we had moved the main computational loops of
our example code and, in doing so, introduced a significant amount of implicit
data transfers. The performance profile for our code shows that for each
iteration the A and Anew arrays are being copied back and forth between the
host and device, four times for the parallel loop version and twice for
the kernels version. Given that the values for these arrays are not needed
until after the answer has converged, let’s add a data region around the
convergence loop. Additionally, we’ll need to specify how the arrays should be
managed by this data region. Both the initial and final values for the A
array are required, so that array will require a copy data clause. The
results in the Anew array, however, are only used within this section of
code, so a create clause will be used for it. The resulting code is shown
below.
Note: The changes required during this step are the same for both versions of
the code, so only the parallel loop version will be shown.
#pragma acc data copy(A[:n][:m]) create(Anew[:n][:m])
while ( error > tol && iter < iter_max )
{
error = 0.0;
#pragma acc parallel loop reduction(max:error)
for( int j = 1; j < n-1; j++)
{
#pragma acc loop reduction(max:error)
for( int i = 1; i < m-1; i++ )
{
Anew[j][i] = 0.25 * ( A[j][i+1] + A[j][i-1]
+ A[j-1][i] + A[j+1][i]);
error = fmax( error, fabs(Anew[j][i] - A[j][i]));
}
}
#pragma acc parallel loop
for( int j = 1; j < n-1; j++)
{
#pragma acc loop
for( int i = 1; i < m-1; i++ )
{
A[j][i] = Anew[j][i];
}
}
if(iter % 100 == 0) printf("%5d, %0.6f\n", iter, error);
iter++;
}
!$acc data copy(A) create(Anew)
do while ( error .gt. tol .and. iter .lt. iter_max )
error=0.0_fp_kind
!$acc parallel loop reduction(max:error)
do j=1,m-2
!$acc loop reduction(max:error)
do i=1,n-2
A(i,j) = 0.25_fp_kind * ( Anew(i+1,j ) + Anew(i-1,j ) + &
Anew(i ,j-1) + Anew(i ,j+1) )
error = max( error, abs(A(i,j) - Anew(i,j)) )
end do
end do
!$acc parallel loop
do j=1,m-2
!$acc loop
do i=1,n-2
A(i,j) = Anew(i,j)
end do
end do
if(mod(iter,100).eq.0 ) write(*,'(i5,f10.6)'), iter, error
iter = iter + 1
end do
!$acc end data
With this change, only the value computed for the maximum error, which is
required by the convergence loop, is copied from the device every iteration.
The A and Anew arrays will remain local to the device through the extent of
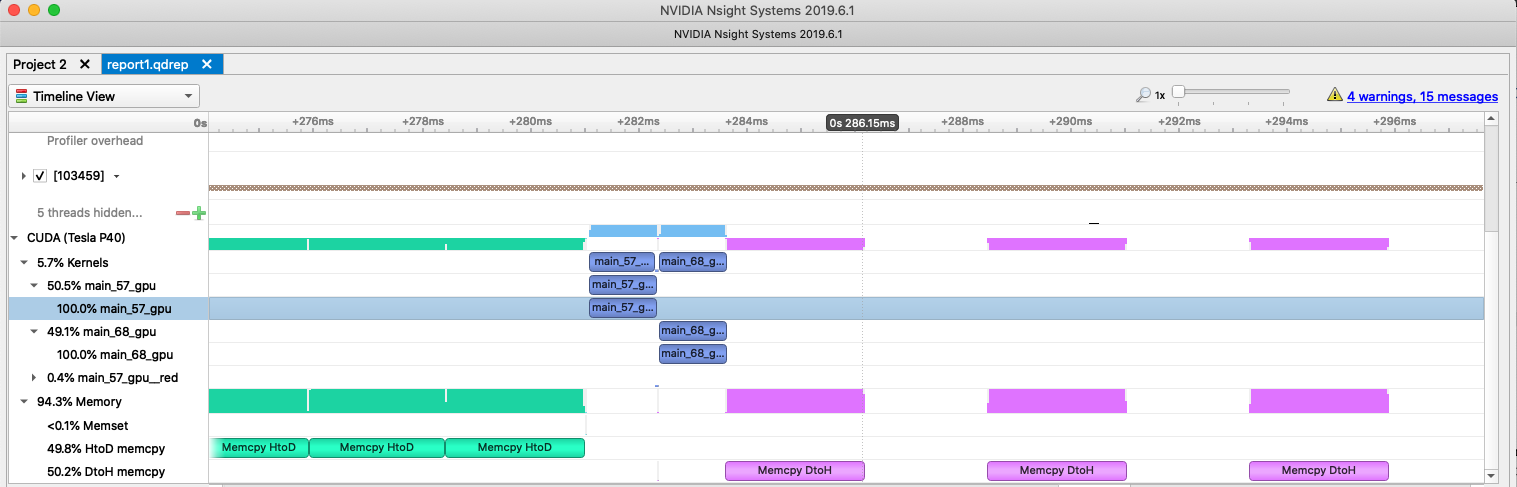
this calculation. Using the NVIDIA NSight Systems again, we see that each
data transfers now only occur at the beginning and end of the data region and
that the time between each iterations is much less.
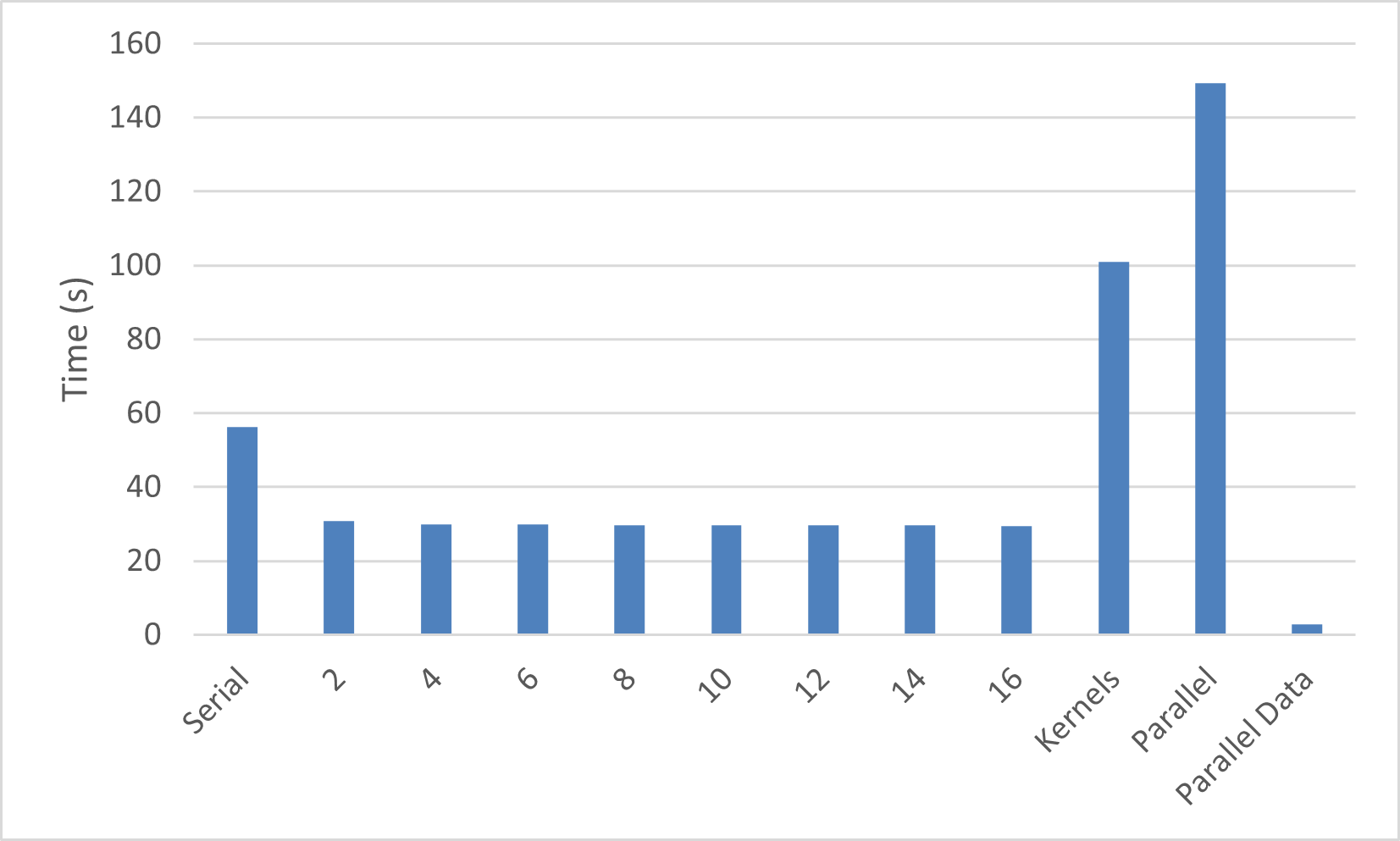
Looking at the final performance of this code, we see that the time for the
OpenACC code on a GPU is now much faster than even the best threaded CPU code.
Although only the parallel loop version is shown in the performance graph,
the kernels version performs equally well once the data region has been
added.
This ends the Jacobi Iteration case study. The simplicity of this implementation generally shows very good speed-ups with OpenACC, often leaving little potential for further improvement. The reader should feel encouraged, however, to revisit this code to see if further improvements are possible on the device of interest to them.