Introduction
This guide presents methods and best practices for accelerating applications in an incremental, performance portable way. Although some of the examples may show results using a given compiler or accelerator, the information presented in this document is intended to address all architectures both available at publication time and well into the future. Readers should be comfortable with C, C++, or Fortran, but do not need experience with parallel programming or accelerated computing, although such experience will be helpful.
Note: This guide is a community effort. To contribute, please visit the project on Github.
Writing Portable Code
The current computing landscape is spotted with a variety of computing architectures: multi-core CPUs, GPUs, many-core devices, DSPs, ARM processors, and FPGAs, to name a few. It is now commonplace to find not just one, but several of these differing architectures within the same machine. Programmers must make portability of their code a forethought, otherwise they risk locking their application to a single architecture, which may limit the ability to run on future architectures. Although the variety of architectures may seem daunting to the programmer, closer analysis reveals trends that show a lot in common between them. The first thing to note is that all of these architectures are moving in the direction of more parallelism. CPUs are not only adding CPU cores but also expanding the length of their SIMD operations. GPUs have grown to require a high degree of block and SIMT parallelism. It is clear that going forward all architectures will require a significant degree of parallelism in order to achieve high performance. Modern processors need not only a large amount of parallelism, but frequently expose multiple levels of parallelism with varying degrees of coarseness. The next thing to notice is that all of these architectures have exposed hierarchies of memory. CPUs have the main system memory, typically DDR, and multiple layers of cache memory. GPUs have the main CPU memory, the main GPU memory, and various degrees of cache or scratchpad memory. Additionally on hybrid architectures, which include two or more different architectures, there exist machines where the two architectures have completely separate memories, some with physically separate but logically the same memory, and some with fully shared memory.
Because of these complexities, it’s important that developers choose a programming model that balances the need for portability with the need for performance. Below are four programming models of varying degrees of both portability and performance. In a real application it’s frequently best to use a mixture of approaches to ensure a good balance between high portability and performance.
Libraries
Standard (and de facto standard) libraries provide the highest degree of portability because the programmer can frequently replace only the library used without even changing the source code itself when changing compute architectures. Since many hardware vendors provide highly-tuned versions of common libraries, using libraries can also result in very high performance. Although libraries can provide both high portability and high performance, few applications are able to use only libraries because of their limited scope.
Some vendors provide additional libraries as a value-add for their platform, but which implement non-standard APIs. These libraries provide high performance, but little portability. Fortunately because libraries provide modular APIs, the impact of using non-portable libraries can be isolated to limit the impact on overall application portability.
Standard Programming Languages
Many standard programming languages either have or are beginning to adopt
features for parallel programming. For example, Fortran 2008 added support
for do concurrent, which exposes the potential parallelism with that loop,
and C++17 added support for std::execution, which enables users to express
parallelism with certain loop structures.
Adoption of these language features is often slow, however, and many standard languages are
only now beginning to discuss parallel programming features for future language
releases. When these features become commonplace, they will provide high
portability, since they are part of a standard language, and if well-designed
can provide high performance as well.
Compiler Directives
When standard programming languages lack support for necessary features compiler directives can provide additional functionality. Directives, in the form of pragmas in C/C++ and comments in Fortran, provide additional information to compilers on how to build and/or optimize the code. Most compilers support their own directives, and also directives such as OpenACC and OpenMP, which are backed by industry groups and implemented by a range of compilers. When using industry-backed compiler directives the programmer can write code with a high degree of portability across compilers and architectures. Frequently, however, these compiler directives are written to remain very high level, both for simplicity and portability, meaning that performance may lag lower-level programming paradigms. Many developers are willing to give up 10-20% of hand-tuned performance in order to get a high degree of portability to other architectures and to enhance programmer productivity. The tolerance for this portability/performance trade-off will vary according to the needs of the programmer and application.
Parallel Programming Extensions
CUDA and OpenCL are examples of extensions to existing programming languages to give additional parallel programming capabilities. Code written in these languages is frequently at a lower level than that of other options, but as a result can frequently achieve higher performance. Lower level architectural details are exposed and the way that a problem is decomposed to the hardware must be explicitly managed with these languages. This is the best option when performance goals outweigh portability, as the low-level nature of these programming languages frequently makes the resulting code less portable. Good software engineering practices can reduce the impact these languages have on portability.
There is no one programming model that fits all needs. An application developer needs to evaluate the priorities of the project and make decisions accordingly. A best practice is to begin with the most portable and productive programming models and move to lower level programming models only as needed and in a modular fashion. In doing so the programmer can accelerate much of the application very quickly, which is often more beneficial than attempting to get the absolute highest performance out of a particular routine before moving to the next. When development time is limited, focusing on accelerating as much of the application as possible is generally more productive than focusing solely on the top time consuming routine.
What is OpenACC?
With the emergence of GPU and many-core architectures in high performance computing, programmers desire the ability to program using a familiar, high level programming model that provides both high performance and portability to a wide range of computing architectures. OpenACC emerged in 2011 as a programming model that uses high-level compiler directives to expose parallelism in the code and parallelizing compilers to build the code for a variety of parallel accelerators. This document is intended as a best practices guide for accelerating an application using OpenACC to give both good performance and portability to other devices.
The OpenACC Accelerator Model
In order to ensure that OpenACC would be portable to all computing architectures available at the time of its inception and into the future, OpenACC defines an abstract model for accelerated computing. This model exposes multiple levels of parallelism that may appear on a processor as well as a hierarchy of memories with varying degrees of speed and addressability. The goal of this model is to ensure that OpenACC will be applicable to more than just a particular architecture or even just the architectures in wide availability at the time, but to ensure that OpenACC could be used on future devices as well.
At its core OpenACC supports offloading of both computation and data from a host device to an accelerator device. In fact, these devices may be the same or may be completely different architectures, such as the case of a CPU host and GPU accelerator. The two devices may also have separate memory spaces or a single memory space. In the case that the two devices have different memories the OpenACC compiler and runtime will analyze the code and handle any accelerator memory management and the transfer of data between host and device memory. Figure 1.1 shows a high level diagram of the OpenACC abstract accelerator, but remember that the devices and memories may be physically the same on some architectures.
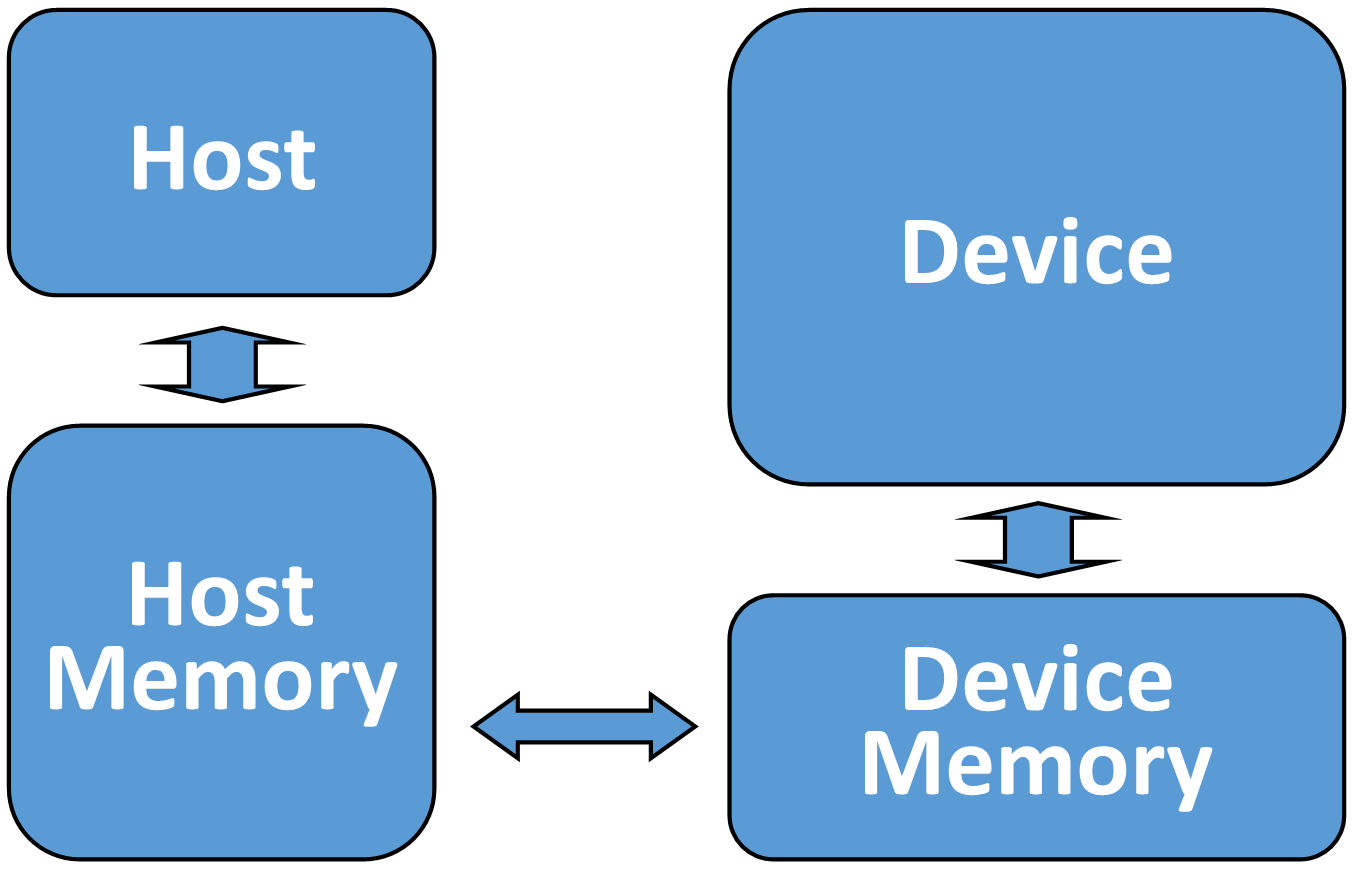
More details of OpenACC’s abstract accelerator model will be presented throughout this guide when they are pertinent.
Best Practice: For developers coming to OpenACC from other accelerator
programming models, such as CUDA or OpenCL, where host and accelerator memory
is frequently represented by two distinct variables (host_A[] and
device_A[], for instance), it’s important to remember that when using OpenACC
a variable should be thought of as a single object, regardless of whether
it’s backed by memory in one or more memory spaces. If one assumes that a
variable represents two separate memories, depending on where it is used in the
program, then it is possible to write programs that access the variable in
unsafe ways, resulting in code that would not be portable to devices that share
a single memory between the host and device. As with any parallel or
asynchronous programming paradigm, accessing the same variable from two
sections of code simultaneously could result in a race condition that produces
inconsistent results. By assuming that you are always accessing a single
variable, regardless of how it is stored in memory, the programmer will avoid
making mistakes that could cost a significant amount of effort to debug.
Benefits and Limitations of OpenACC
OpenACC is designed to be a high-level, platform independent language for
programming accelerators. As such, one can develop a single source code that
can be run on a range of devices and achieve good performance. The simplicity
and portability that OpenACC’s programming model provides sometimes comes at a
cost to performance. The OpenACC abstract accelerator model defines a least
common denominator for accelerator devices, but cannot represent architectural
specifics of these devices without making the language less portable. There
will always be some optimizations that are possible in a lower-level
programming model, such as CUDA or OpenCL, that cannot be represented at a high
level. For instance, although OpenACC has the cache directive, some uses of
shared memory on NVIDIA GPUs are more easily represented using CUDA. The same
is true for any host or device: certain optimizations are too low-level for a
high-level approach like OpenACC. It is up to the developers to determine the
cost and benefit of selectively using a lower level programming language for
performance critical sections of code. In cases where performance is too
critical to take a high-level approach, it’s still possible to use OpenACC for
much of the application, while using another approach in certain places, as
will be discussed in a later chapter on interoperability.